Sales
| +91-8800766220
| +91-120-6619504
Support
| 0120-62-77777
How Important is to Have a Latency-optimized Architecture?
Jul 28,2021
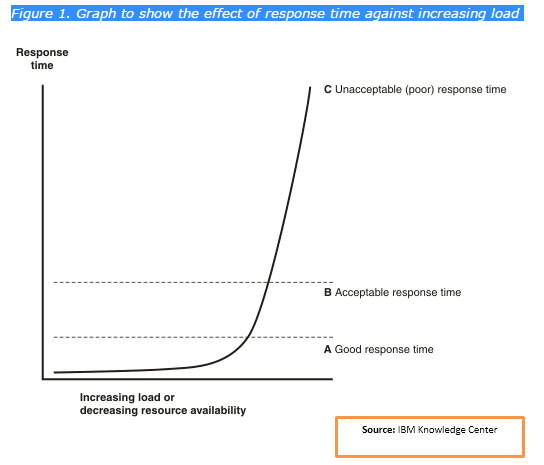
In the world of electronic commerce, one of the main topics of boardroom discussion among the CTOs, CEOs, CFOs, and CIOs is related to latency. As the dependency on virtualized and elastic cloud infrastructure is at its peak, businesses are in pursuit of integrating steadfast yet resilient cloud networking techniques that prevent latency and data loss probabilities. Network utilization and latency are inversely proportional to each other. Networking works in accordance with the laws of physics. Light travels through a vacuum at 186,282 miles per second; however, sometimes owing to refractive index of glass or electron movement delay in copper, the speed at which data gets transmitted slackens, which reduces the given figure to somewhere around 122,000 miles per second.
To iron out the latency issue, efforts should be planned with an objective to minimize the distance that the data must travel. In this light, organizations have refurbished their systems to balance response time requirements for delivering always-up, always-available critical business applications.
Let’s first understand what does response time mean and why it is believed to be an impression setter:
Response time is the duration of the time that a system takes to respond to a request for service. The requested service can be pertaining to a webpage load, memory fetch, complex database query, or disk IO.
Well, end-user response-time metric matters a lot as it acts as an impression setter with respect to the performance of your applications. It is inevitable to check that application or component does not make an end-user ponder whether or not it has received the requested inputs. Moreover, being vigilant that the requested applications are responded within the specified time-frame prior to their information becomes obsolete helps in capturing subjective performance. In this context, experts insist on practicing particular methodologies and suggest enterprises to go by the set parameters that clearly connote a difference between performance needs and goals.
Understanding the criticality of response time in today’s electronic trading ecosphere, businesses spanning across different verticals like, banking, education, research firms, healthcare, and even Web 2.0 firms are astutely focusing on expeditious response time for their delivered applications.
Variations in Response Time Lead to Poor User Experience
Do you know how a few seconds of delay in response time can take a toll on your pre-set performance and productivity goals? Delay in responses leaves a bad impression on the end-user. Users never want to return to the same platform again, if the application or the content they have requested is not displayed within ideal time limits. In other business verticals, it is noted that even 1 millisecond of latency could cost around $100 million per year. Moreover, this figure has gone to costlier lengths to limit latency as much as possible.
How to Deal with Latency Issues:
Each router or switch integrated in the data path adds an obvious amount of delay as the data packet is received, processed, and then sent. The best way to deal with latency is to maintain all the application and middleware components. Furthermore, an astute architectural approach should be practiced all the time so that response times are consistently and measurably augmented across a host of cloud-based applications.
In particular, businesses need to adopt advanced approach leaving obsolete niche and proprietary technologies behind to build a data center architecture based upon industry proven standards and widely used technologies as these metrics can only ascertain performance-driven cloud deployments. This is not the only thing that you need to focus upon, however you also need to check that latency optimization is at the infrastructure level that can meet the requirement for the approaching years. Technically, network latencies must be optimized across four key attributes:
- By curtailing latency of each network node
- By cutting back the number of nodes
- By mitigating the network congestion
- By reducing the latency allied to transport protocol
Building a Latency-sensitive Cloud network bestows best outcomes:
While planning for latency-optimized platform, it is important that workloads are build using distributed compute architecture. In order to augment the response time, right from the compute to network latencies, every aspect should be given same focus and weight. In conventional setups usually commodity servers are utilized for computing purpose and freedom to optimize latency is quite an intricate procedure. The best way to make latency a distant phenomenon for your users is to deploy a cloud network as it comprises of fabric-wide optimization to abate transport latencies.
The Bottom Line:
To keep your applications always up and running, balance between compute and network latencies needs to be reduced simultaneously. The approach to trim down latency issues should be a holistic endeavor that takes into account the end-to-end data system and focuses upon decreasing latency all through the protocol layers. Remember, right optimization techniques help in delivering low latency while increasing the operational value.
If you are looking out for data center or cloud hosting solutions where performance is the prime focus and latency is not an issue, you can connect to our experts at: 1800-212-2022.
Subscribe
0 Comments
AWS Standard Consulting Partner


Alibaba Cloud



Cyfuture Ltd.
The Cricket Barn
Tiverton
Exeter
EX16 8ND
Ph: 1-888-795-2770
E-mail: [email protected]